
[ad_1]
Un récent Intelligence artificielle naturelle Étude examinée l’efficacité de Classificateurs d’intelligence artificielle (IA) basés sur l’audio pour prédire l’état d’infection du coronavirus-2 du syndrome respiratoire aigu sévère (SRAS-CoV-2). Le SRAS-CoV-2 est l’agent causal de la pandémie de maladie à coronavirus 2019 (COVID-19).
 Étude: Les classificateurs audio basés sur l’IA ne montrent aucune preuve d’amélioration du dépistage du COVID-19 par rapport aux simples vérificateurs de symptômes. Source de l’image : Aliaksandra Post / Shutterstock
Étude: Les classificateurs audio basés sur l’IA ne montrent aucune preuve d’amélioration du dépistage du COVID-19 par rapport aux simples vérificateurs de symptômes. Source de l’image : Aliaksandra Post / Shutterstock
arrière-plan
Puisque l’infection par le SRAS-CoV-2 peut provoquer des manifestations symptomatiques et asymptomatiques, il est important de développer des tests précis pour éviter une quarantaine générale de la population. Des études antérieures ont montré que les classificateurs basés sur l’IA formés sur les données audio respiratoires pourraient identifier le statut du SRAS-CoV-2.
Bien que ces études aient démontré l’efficacité des classificateurs basés sur l’IA, de nombreux défis sont apparus lors de leur application dans des environnements réels. Certains facteurs qui ont entravé les applications du classificateur basé sur l’IA étaient le biais d’échantillonnage, les données non validées sur le statut COVID-19 des participants et le délai entre l’infection et l’enregistrement audio. Il est important de déterminer si les biomarqueurs audio du COVID-19 sont uniques à l’infection par le SRAS-CoV-2 ou s’il s’agit de signaux sonores inappropriés.
À propos de l’étude
L’étude actuelle s’est concentrée sur la détermination si les classificateurs audio peuvent être utilisés avec précision pour le dépistage du COVID-19. Un ensemble de données de réaction en chaîne par polymérase (PCR) à grande échelle lié au dépistage audio du COVID-19 (ABCS) a été utilisé. Les participants du programme d’évaluation en temps réel de la transmission communautaire (REACT) et du service Test and Trace (T+T) du National Health Service (NHS) ont été invités pour cette étude. Toutes les données démographiques pertinentes ont été extraites des ensembles de données T+T/REACT.
Les participants ont été invités à répondre aux questions du sondage et à enregistrer quatre clips audio. Lors des enregistrements audio, il leur était demandé de lire une phrase spécifique, puis d’expirer trois fois de suite, en émettant un son « ha ». De plus, les participants ont été invités à enregistrer une toux violente une à trois fois de suite. Tous les enregistrements ont été documentés au format .wav. La qualité des enregistrements audio a été évaluée et 5 157 enregistrements ont été supprimés en raison de problèmes de qualité.
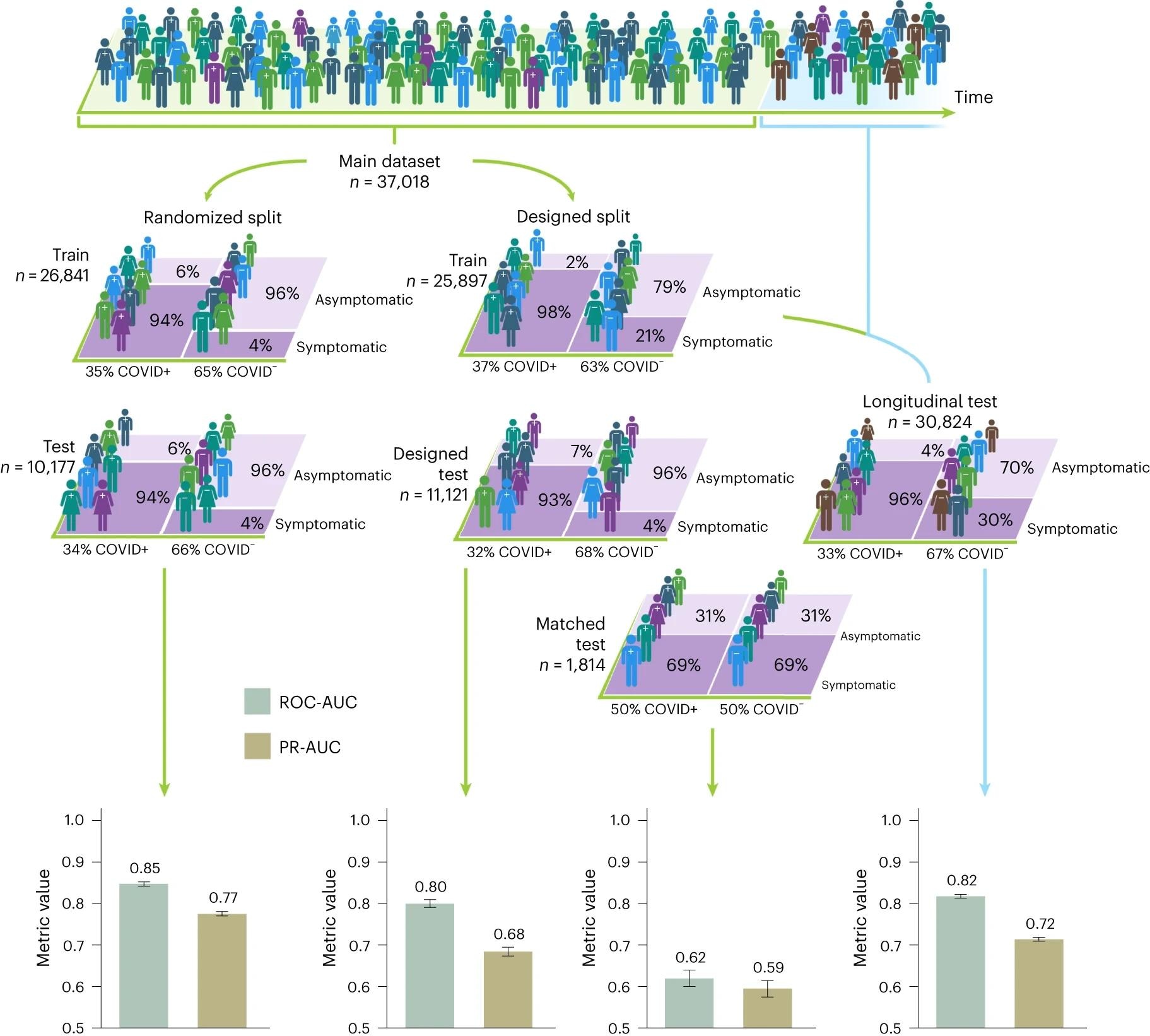 Les chiffres humains représentent les participants à l’étude et leur statut d’infection au COVID-19 correspondant, avec différentes couleurs représentant différentes caractéristiques démographiques ou symptomatiques. Lorsque les participants sont répartis au hasard en ensembles de formation et de tests, les modèles de répartition aléatoire fonctionnent bien dans la détection du COVID-19, atteignant des AUC supérieures à 0,8 ; Cependant, on observe que les performances de l’ensemble de tests d’appariement chutent à une AUC estimée entre 0,60 et 0,65, une AUC de 0,5 représentant une classification aléatoire. Des performances de classification excessives sont également observées sur des ensembles de tests conçus en dehors de la distribution, tels que : B. l’ensemble de tests conçu, dans lequel un ensemble sélectionné de groupes démographiques apparaît exclusivement dans l’ensemble de tests, et l’ensemble de tests longitudinaux, dans lequel il n’y a pas de chevauchement des délais de livraison entre les instances de train et de test. Les intervalles de confiance à 95 % calculés à l’aide de la méthode d’approximation normale sont présentés avec les n numéros correspondants du train et des ensembles de test.
Les chiffres humains représentent les participants à l’étude et leur statut d’infection au COVID-19 correspondant, avec différentes couleurs représentant différentes caractéristiques démographiques ou symptomatiques. Lorsque les participants sont répartis au hasard en ensembles de formation et de tests, les modèles de répartition aléatoire fonctionnent bien dans la détection du COVID-19, atteignant des AUC supérieures à 0,8 ; Cependant, on observe que les performances de l’ensemble de tests d’appariement chutent à une AUC estimée entre 0,60 et 0,65, une AUC de 0,5 représentant une classification aléatoire. Des performances de classification excessives sont également observées sur des ensembles de tests conçus en dehors de la distribution, tels que : B. l’ensemble de tests conçu, dans lequel un ensemble sélectionné de groupes démographiques apparaît exclusivement dans l’ensemble de tests, et l’ensemble de tests longitudinaux, dans lequel il n’y a pas de chevauchement des délais de livraison entre les instances de train et de test. Les intervalles de confiance à 95 % calculés à l’aide de la méthode d’approximation normale sont présentés avec les n numéros correspondants du train et des ensembles de test.
Résultats de l’étude
Dans cette étude, un ensemble de données d’acoustique respiratoire a été collecté auprès de 67 842 personnes. Parmi eux, 23 514 personnes ont été testées positives au COVID-19. Toutes les données ont été liées aux résultats des tests PCR. Il convient de noter que le plus grand nombre de participants négatifs au COVID-19 ont été recrutés à partir de six cycles de REACT par rapport au canal T+T.
L’ensemble de données considéré dans cette étude a montré une couverture prometteuse dans toute l’Angleterre. Aucune association significative n’a été trouvée entre la situation géographique et le statut COVID-19. Le niveau le plus élevé de disparité en matière de COVID-19 a été constaté à Cornwall. Une étude précédente suggérait un biais de recrutement dans ABCS, particulièrement lié à l’âge, à la langue et au sexe, à la fois dans les données de formation et dans les ensembles de tests. Malgré ce biais, l’ensemble des données de formation était équilibré en fonction de l’âge et du sexe dans les sous-groupes positifs et négatifs pour la COVID.
Conformément aux études précédentes, l’analyse non ajustée menée dans cette étude a montré que les classificateurs de l’IA peuvent prédire le statut du COVID-19 avec une grande précision. Cependant, en comparant les facteurs de confusion mesurés, de mauvaises performances des classificateurs d’IA dans la détection du statut SARS-CoV-2 ont été observées.
Sur la base des résultats, certaines lignes directrices ont été proposées dans la présente étude afin de corriger les effets du biais de recrutement pour les études futures. Certaines des recommandations sont énumérées ci-dessous :
- Les échantillons audio stockés dans les référentiels doivent contenir des détails sur les critères de recrutement de l’étude. En outre, les informations pertinentes sur les individus, notamment le sexe, l’âge, l’heure du test COVID-19, les symptômes et l’emplacement du SRAS-CoV-2, doivent être documentées avec l’enregistrement audio.
- Tous les facteurs de confusion doivent être identifiés et réconciliés pour contrôler les biais d’embauche.
- La conception expérimentale doit être développée en tenant compte des éventuels biais. Dans la plupart des cas, l’appariement des données entraîne une réduction de la taille de l’échantillon. Les études observationnelles recrutent des participants qui se concentrent sur la plus grande capacité possible à attribuer les facteurs de confusion mesurés.
- Les valeurs de prédiction des classificateurs doivent être comparées aux résultats du protocole standard.
- La précision des prédictions des classificateurs d’IA doit être évaluée. Cependant, l’exactitude prédictive, la sensibilité et la spécificité varient en fonction du groupe cible.
- L’utilité des classificateurs doit être évaluée pour chaque résultat de test.
- L’étude de réplication doit être menée dans des cohortes randomisées. De plus, des études pilotes doivent être menées dans des contextes réels basés sur une utilité spécifique au domaine.
Conclusions
L’étude actuelle présente des limites, notamment la possibilité de facteurs de confusion potentiels non mesurés dans les canaux de recrutement REACT et T+T. Par exemple, le test PCR du COVID-19 a été réalisé plusieurs jours après l’auto-dépistage des symptômes. En revanche, le test PCR dans REACT a été effectué à un moment prédéterminé, quel que soit l’apparition des symptômes. Même si la majorité des facteurs confondants étaient cohérents, il existe une possibilité qu’une variation prédictive résiduelle existe.
Malgré les limites, cette étude a mis en évidence la nécessité de développer des techniques précises d’évaluation de l’apprentissage automatique pour obtenir des résultats impartiaux. De plus, il a été démontré que les facteurs perturbateurs sont difficiles à détecter et à contrôler dans de nombreuses applications d’IA.
Référence du magazine :
- Coppock, H. et coll. (2024) Les classificateurs d’IA basés sur l’audio ne montrent aucune preuve d’amélioration du dépistage du COVID-19 par rapport aux simples vérificateurs de symptômes. Intelligence artificielle naturelle. 1-14. DOI : 10.1038/s42256-023-00773-8, https://www.nature.com/articles/s42256-023-00773-8
[ad_2]
Source